Benchmarking checksum tools
I was curious to see which checksumming/hashing tool would be the fastest on my machine. This is helpful when copying files around and checking if they were not corrupted.

These are the checksumming tools I’ll benchmark, from GNU coreutils and xxHash:
b2sum: 512-bit hash (BLAKE2b)cksum: 32-bit CRC checksum - non-cryptographic algorithmmd5sum: 128-bit hash - cryptographically brokensha1sum: 160-bit hash - cryptographically brokensha224sum: 224-bit hashsha256sum: 256-bit hashsha384sum: 384-bit hashsha512sum: 512-bit hashXXH128: 128-bit hash - non-cryptographic algorithm.
I want to see their performance on small (1 KiB), medium (1 MiB), and large (1 GiB) files. For testing purposes, I’ll generate random data:
dd if=/dev/urandom of=1K bs=1K count=1
dd if=/dev/urandom of=1M bs=1M count=1
dd if=/dev/urandom of=1G bs=1M count=1024I’ll use hyperfine to run the benchmarks:
for file_size in 1K 1M 1G; do
hyperfine --warmup 3 --shell=none --min-runs 20 --export-json "${file_size}.json" \
"b2sum ${file_size}" \
"cksum ${file_size}" \
"md5sum ${file_size}" \
"sha1sum ${file_size}" \
"sha224sum ${file_size}" \
"sha256sum ${file_size}" \
"sha384sum ${file_size}" \
"sha512sum ${file_size}" \
"xxhsum -H2 ${file_size}"
doneI got many warnings about statistical outliers when running these benchmarks,
even when I had nothing but hyperfine and NeoVim (and the OS) running. I’ll
ignore that for now.
For 1 KiB files, hyperfine run each command more than 1000 times; for 1 MiB
files, it run at least 600 times; and for 1 GiB files, 20 times only.
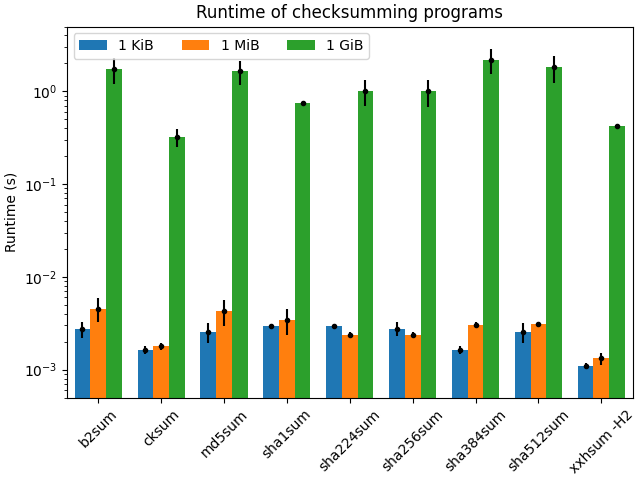
The results on my laptop (AMD Ryzen 7 PRO 5875U, NVMe) are very interesting:
Summary
xxhsum -H2 1K ran
1.64 ± 0.33 times faster than sha512sum 1K
1.67 ± 0.46 times faster than md5sum 1K
1.73 ± 0.44 times faster than sha1sum 1K
2.60 ± 0.75 times faster than sha384sum 1K
2.91 ± 0.52 times faster than sha256sum 1K
2.91 ± 0.51 times faster than sha224sum 1K
2.91 ± 0.52 times faster than b2sum 1K
2.95 ± 0.53 times faster than cksum 1K
Summary
xxhsum -H2 1M ran
1.33 ± 0.14 times faster than cksum 1M
1.72 ± 0.17 times faster than sha256sum 1M
2.46 ± 0.81 times faster than b2sum 1M
2.84 ± 0.69 times faster than sha224sum 1M
3.14 ± 0.23 times faster than sha1sum 1M
3.66 ± 0.80 times faster than sha384sum 1M
4.05 ± 0.27 times faster than sha512sum 1M
4.16 ± 0.25 times faster than md5sum 1M
Summary
cksum 1G ran
1.19 ± 0.29 times faster than xxhsum -H2 1G
2.90 ± 0.68 times faster than sha1sum 1G
3.34 ± 1.02 times faster than sha256sum 1G
3.74 ± 1.23 times faster than sha224sum 1G
6.90 ± 2.29 times faster than md5sum 1G
6.97 ± 2.09 times faster than b2sum 1G
7.16 ± 2.22 times faster than sha512sum 1G
7.16 ± 2.18 times faster than sha384sum 1GI also wanted to play with Matplotlib, so I made a nice plot of the actual runtimes, the lower the better. Note the log scale:
Here’s the code in case you want to play with it: matplot.py; and my raw data: 1K.json, 1M.json, and 1G.json.
For small and medium files, XXH128 (xxhsum -H2) was the absolute fastest. For
large files, CRC (cksum) and XXH128 have roughly the same performance, when
you take into account the measurement errors.
The difference in runtime from 1 KiB to 1 MiB is way smaller than from 1 MiB to 1 GiB, even though each “step” is relatively the same (1024 times). My CPU has 16 MiB L3 cache, it can fit my small and medium testing data just fine (1 KiB even fits L1d) but not the large one, that one comes from the disk and took two orders of magnitude longer on all cases.
I’m very surprised about sha224sum and sha256sum: they were faster for 1
MiB than for 1 KiB files. I expected the larger the file size the longer it
would take to compute the hash, but not for these two.
I’m disappointed at b2sum. I was using it all the time because I thought it
would always outperform md5sum. But that’s not the case, their performance is
similar when you compare only these two. Still, I prefer b2sum over md5sum:
both are cryptographic hashes, but BLAKE2b is not broken.
The winner, to me, is xxhsum -H2 and that’s what I’ll be using from now on to
check data integrity. It is the fastest in my tests and is available in most
Linux distributions (and also in FreeBSD ports). It doesn’t give a
cryptographically secure hash, but that is not needed for this use case: I want
to check if the files were not corrupted, I’m not hashing passwords or anything
like that.